SugarCRM and Caching with APC
At my day job, I'm responsible for everything that is Operations at SugarCRM including our OnDemand environment where we host SugarCRM for a large number of our customers. The web clusters are a not too surprising Open Source stack including nginx, wackamole, Apache, PHP, MySQL, CentOS, memcache, etc, but because of how SugarCRM works, we do run into some interesting challenges from time to time. Our engineering team develops a single product that can be deployed on customer servers, in our ondemand environment, and anywhere in the cloud, which means that in our environment each customer instance of SugarCRM lives in it's own silo. This puts our own unique spin on the common SaaS challenge of scaling up while keeping response times as low as possible.
One of the key components in keeping response times low is PHP opcode caching. When I started at SugarCRM a few years ago, we were using Zend Platform for opcode caching, session clustering, and a few other things. It did a fine job of the opcode caching but one of our "standard procedures" was to restart the Zend session clustering daemon whenever a customer reported certain kinds of problems. Not good! To permanently resolve this, help move us towards a full Open Source stack (since we are an Open Source company!), and to simplify our architecture, we moved to using APC for opcode caching (and memcached for session clustering).
The APC performance gains were similar to using Zend, but we didn't have any issues with APC requiring service restarts for close to 2 years. Over these two years we have continued to add web servers to our OnDemand cluster as the number of customers increased, and a few weeks ago Apache started (seemingly randomly) getting backed up with all of it's slots in use "Sending Reply". A simple `apachectl reload` would fix this, but it was eerily similar to the days of Zend. Due to the number of other ongoing projects, I didn't have time to investigate this much so I set up an alarm in our monitoring system so that we would get alarms before the web server got completely backed up and could proactively fix the issue.
Unrelated, yesterday I was looking at some of our metrics and noticed that our APC cache hit rate was a lot lower than it should be due to a high "Cache Full Count" (The Cache Full Count number was 10% of the size of the Cache Hit Count). We weren't directly monitoring this and I remember making sure the cache was big enough when this was initially set up, but that was from when we had a much smaller OnDemand customer base. To fix this, I bumped up the cache size from 128M to 512M and our configuration management system slowly started pushing out the changes. Cache Full Count was reset to 0 and stayed at 0, and the hit rate went from ~70% to ~90% across the cluster. Problem Solved! Or so I thought.
A little later on in the day, the web servers started getting backed up, much more quickly than before and all at the same time, and it was starting to cause timeouts for some customers. The proverbial monkeys in our application had gotten mad at the fan.
With a much bigger problem, I did some deeper debugging using strace and the "Sending Reply" apache processes all seemed to be spinlocked on a futex(FUTEX_WAKE) call. Could this be APCs fault? I disabled APC across the cluster and the problem went away, but had to figure out a way to fix this because no APC means a significant increase in the minimum load time to every single page load in our system. Digging through source code and Googling around, I came across How to Dismantle an APC Bomb which explains a set of symptoms that seemed very familiar. The cause was explained as contention caused by apc_store calls which is in the User Cache portion of APC andnot the opcode cache, which gave me an idea: just disable the user cache.
With SugarCRM, this can be done by setting 'external_cache_disabled' or 'external_cache_disabled_apc' in config.php, but I didn't really want to touch thousands of config.php files, so I looked in our code and found:
elseif(function_exists("apc_store") && empty($GLOBALS['sugar_config']['external_cache_disabled_apc']))'
SugarCRM checks if apc_store exists to see if it can use APC, so I simply added apc_store to disable_functions in our php.ini template, re-enabled APC, tested out the changes, and pushed this out to the cluster.
This ended up being the problem and the solution. It turns out that increasing the memory available to APC meant that things were staying in the cache longer which made the contention issue even worse. SugarCRM's use of a user cache simply doesn't scale well in a massive clustered environment, and with it disabled, the opcode cache can do a better job. Hit rates are up to 92% to 99% across the cluster, and response times are down. Below is a sanitized graph of response times to a test instance designed to represent the worst response times across the OnDemand cluster:
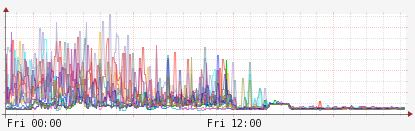
- APC's memory was increased from 128M to 512M a little after the dotted red line at 12:00. This improved consistency of 'worst case' response times significantly
- Sometime between 1pm and 2pm, things started to get Very Bad and while response times were still down, web servers were crashing left and right
- At 2:12, APC was disabled completely. Minimum response times went up but things got suspiciously consistent
- After over an hour of investigation and testing, at around 3:20, APC was re-enabled with apc_store disabled, response times went back down, and the response time consistency remained.
I'm glad this issue happened after peak hours on a Friday, and I'm looking forward to seeing how this solution affects response times during peak load periods next week. If you're running SugarCRM at any kind of scale, this may be something to consider.
comments powered by
